Membership#
An adversary can leverage a membership inference attack that takes advantage of query answers on a sequestered dataset to infer if a particular individual exists in the sequestered dataset. There are situations in which knowing if an individual exists within a sequestered dataset poses risk to the individual.
The membership attacks in this notebook come from DSSUV’15, Robust Traceability from Trace Amounts.
This notebook makes use of the Public Use Microdata Sample (PUMS), obtained from the Census Bureau’s American Community Survey (ACS). Attacks like the one demonstrated in this notebook motivate the use of statistical disclosure limitation techniques like differential privacy.
[1]:
import numpy as np
import pandas as pd
import time
np.random.seed(123)
Membership Attacks#
An attacker wants to determine if Alice, an individual from the population, is a member of a sequestered dataset. Consider the sequestered dataset to be a sample from a broader population.
It is assumed that the attacker is given the answers to a mean query mechanism applied to the sequestered dataset. The attacker collects the public information for Alice, as well as the public information for other individuals from the population (the reference sample).
The gist of the attack is that if Alice is more similar to the query answers than the reference sample is to the query answers, then Alice is likely a member of the sequestered dataset.
The first attack comes from figure 1, where the reference sample is assumed to be of size 1.
[2]:
def membership_attack_fig_1(individual, answers, reference_samples, delta=.05):
"""Perform membership attack using dwork et al. test statistic.
See figure 1 in https://privacytools.seas.harvard.edu/files/privacytools/files/robust.pdf
:param individual: y, a boolean vector of shape (d,)
:param answers: q, a float vector with elements in [0, 1] of shape (d,)
:param reference_samples: z, a boolean vector of length (1, d)
:param delta: statistical significance
:return: True if alice is in data with (1-delta)100% confidence."""
individual = individual * 2 - 1
answers = answers * 2 - 1
reference_samples = reference_samples * 2 - 1
alice_similarity = np.dot(individual, answers) # cosine similarity
reference_similarity = np.dot(reference_samples[0], answers)
statistic = alice_similarity - reference_similarity
d = len(individual)
tau = np.sqrt(8 * d * np.log(1 / delta))
return statistic > tau
The second attack comes from figure 2, a generalization of figure 1 where the reference sample is larger. While the implementation is not as intuitive, it has greater power than figure 1.
[3]:
def membership_attack_fig_2(individual, answers, reference_samples, delta=.05):
"""Perform membership attack using dwork et al. test statistic.
See figure 2 in https://privacytools.seas.harvard.edu/files/privacytools/files/robust.pdf
:param individual: y, a boolean vector of shape (d,)
:param answers: q, a float vector with elements in [0, 1] of shape (d,)
:param reference_samples: z, a boolean vector of length (*, d)
:param delta: statistical significance
:return: True if alice is in data with (1-delta)100% confidence."""
individual = individual * 2 - 1
answers = answers * 2 - 1
reference_samples = reference_samples * 2 - 1
z, w = reference_samples[0], reference_samples[1:].mean(axis=0)
m, d = reference_samples[1:].shape
alpha = np.sqrt(1 / m)
eta = 2 * alpha
statistic = np.dot(individual - z, np.clip(answers - w, -eta, eta))
tau = 4 * alpha * np.sqrt(d * np.log(1 / delta))
return statistic > tau
Both of these attacks have low power compared to a Monte Carlo simulation of the null distribution.
Example#
In the following examples, we will consider the population to be 100 individuals from the PUMS dataset. For simplicity, we are assuming all columns are public. Since the tests expect boolean data, we also provide a function to project from a real dataset to a boolean predicate space. We’ll be conducting our tests on the projected boolean space.
[4]:
population: pd.DataFrame = pd.read_csv(
"https://raw.githubusercontent.com/opendp/cs208/main/spring2022/data/FultonPUMS5sample100.csv")
def make_boolean_projection(d_in, d_out=1):
"""Returns a (pseudo)random vector predicate function by hashing data."""
prime = 691
desc = np.random.randint(prime, size=(d_in, d_out))
# this predicate maps data into a ndarray of booleans of size [n, d_out]
# (where `@` is the dot product and `%` modulus)
return lambda data: ((data.values @ desc) % prime % 2).astype(bool)
def draw(data: pd.DataFrame, sample_size: int):
"""Returns `sample_size` rows randomly from `data`, and the rest"""
indices = np.arange(len(population))
np.random.shuffle(indices)
return population.iloc[indices[:sample_size]], population.iloc[indices[sample_size:]]
def execute_exact_query(data):
"""Computes the mean of each attribute."""
return data.mean(axis=0)
To set up this problem, we’ll first create a sequestered dataset, sampled from the population. In practice, this sequestered dataset may be from, for example, a medical trial, or polls conducted by a political party. In those cases, the selection mechanism isn’t a simple sample, and the strength of the attack may be increased.
[5]:
sequestered_data, rest = draw(population, 10)
At this point the attacker takes over. The attacker builds a projection that maps data into a boolean space in which the tests can be conducted. He then collects the information he needs- public information for Alice, query answers on the sequestered data, and reference samples from the population. Keep in mind that the attacker does not need access to the sequestered data to retrieve the public information for Alice and the reference samples.
If the membership attack evaluates to True, then the attacker can be 95% confident that Alice is a member of the sequestered dataset. If the membership attack evaluates to False, it is inconclusive if Alice is a member of the sequestered dataset.
[6]:
# Projects the real-valued dataset into a boolean space with `d_out` columns
project = make_boolean_projection(len(population.columns), d_out=4000)
# Attacker computes the means of each of the attributes of the data in the projected space
# An attacker can still execute this attack on a query interface via predicates
answers = execute_exact_query(project(sequestered_data))
# Attacker collects a reference sample from the population
reference_samples = project(population.sample(1))
# Attacker collects public info for Alice
alice = project(sequestered_data.sample(1))[0]
membership_attack_fig_1(
individual=alice,
answers=answers,
reference_samples=reference_samples,
delta=.05)
[6]:
True
The following example is similar, but we expect the test not to pass, because Anita is not a member of the sequestered dataset.
[7]:
# Attacker collects public info for Anita
anita = project(rest.sample(1))[0]
membership_attack_fig_1(
individual=anita,
answers=answers,
reference_samples=reference_samples,
delta=.05)
[7]:
False
Simulations#
In the following simulations, we will conduct the membership attack thousands of times on different sequestered datasets, random projections, choices of alice, and reference samples, to see how the attack performs as we vary the predicate space dimensionality.
[8]:
def simulate_attacks(
query,
membership_attack, delta,
sample_size, reference_size,
num_predicates, num_trials):
"""Simulates `membership_attack` many times for different boolean space dimensionalities.
:param query: a function that maps data to query answers
:param membership_attack: either membership_attack_fig_1 or membership_attack_fig_2
:param delta: statistical significance of the result
:param sample_size: number of records to sample for the sequestered dataset
:param reference_size: number of referents to sample from the population
:param num_predicates: A vector of boolean space dimensionalities to test
:param num_trials: number of membership attacks to conduct for each boolean space dimensionality
:return: Tuple[np.ndarray, np.ndarray]; A vector false positive rates, and a vector of true positive rates
"""
fp_results = []
tp_results = []
for d in num_predicates:
fp = 0
tp = 0
print('Predicate space dimensionality:', d)
start_time = time.time()
for i in range(num_trials):
if i % (num_trials // 10) == 0:
print(f"{i / num_trials:.0%} ", end="")
# split the population into the sequestered data, and the rest
sequestered_data, rest = draw(population, sample_size)
# build new projection each trial (which contains new random predicates)
projection = make_boolean_projection(len(population.columns), d)
# answers to queries on the dataset to be attacked
answers = query(projection(sequestered_data))
# collect a reference sample from the population
reference_samples = projection(rest.sample(reference_size))
# collect an individual from the attacked dataset
alice = projection(sequestered_data.sample(1))[0]
tp += membership_attack(
individual=alice, answers=answers,
reference_samples=reference_samples, delta=delta)
# collect an individual from the population
anita = projection(rest.sample(1))[0]
fp += membership_attack(
individual=anita, answers=answers,
reference_samples=reference_samples, delta=delta)
print(f"100% ~ {round(time.time() - start_time)} seconds (tp:{tp},fp:{fp})")
fp_results.append(fp / num_trials)
tp_results.append(tp / num_trials)
return fp_results, tp_results
def plot_fpr_tpr(num_predicates, fp_results, tp_results):
import matplotlib.pyplot as plt
plt.plot(num_predicates, fp_results)
plt.xlabel("Number of Predicates")
plt.ylabel("False Positive Rate")
plt.ylim(bottom=0., top=1.)
plt.title("False Positive Rate as Number of Predicates Increases")
plt.show()
plt.plot(num_predicates, tp_results)
plt.xlabel("Number of Predicates")
plt.ylabel("True Positive Rate")
plt.ylim(bottom=0., top=1.)
plt.title("True Positive Rate as Number of Predicates Increases")
plt.show()
In this attack we use the membership attack from figure 1, and vary the predicate space to up to 1000 predicates.
[9]:
num_predicates = np.arange(1, 6) * len(population) * 2
fp_results, tp_results = simulate_attacks(
execute_exact_query,
membership_attack_fig_1,
sample_size=5,
reference_size=1,
num_predicates=num_predicates,
num_trials=1000,
delta=0.05)
print("FPR", fp_results)
print("TPR", tp_results)
plot_fpr_tpr(num_predicates, fp_results, tp_results)
Predicate space dimensionality: 200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:1,fp:0)
Predicate space dimensionality: 400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:84,fp:0)
Predicate space dimensionality: 600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 2 seconds (tp:496,fp:0)
Predicate space dimensionality: 800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 2 seconds (tp:897,fp:0)
Predicate space dimensionality: 1000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 2 seconds (tp:995,fp:0)
FPR [0.0, 0.0, 0.0, 0.0, 0.0]
TPR [0.001, 0.084, 0.496, 0.897, 0.995]

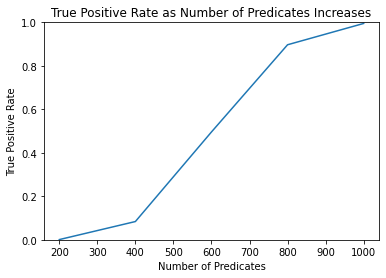
The test doesn’t identify members outside of the sequestered dataset (false positive rate of zero), and becomes more powerful as the number of predicates increases (true positive rate increasing).
These results look very significant, but keep in mind that the size of the sequestered dataset sample_size is only 5. Such a small sample size makes the query answers more distinctive, thus making it much easier to distinguish Alice.
In this second simulation, we increase the sample size to a relatively large 30% of the population. In order to maintain power on the membership attack, we use the hypothesis test from figure 2 instead, collect a larger reference sample, and increase the number of predicates.
[10]:
# Run a more powerful attack with a much larger sample_size and more predicates
num_predicates = np.arange(1, 21) * len(population) * 2
fp_results, tp_results = simulate_attacks(
execute_exact_query,
membership_attack_fig_2,
sample_size=30,
reference_size=50,
num_predicates=num_predicates,
num_trials=100,
delta=0.05)
print("FPR", fp_results)
print("TPR", tp_results)
plot_fpr_tpr(num_predicates, fp_results, tp_results)
Predicate space dimensionality: 200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 0 seconds (tp:5,fp:0)
Predicate space dimensionality: 400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 0 seconds (tp:2,fp:0)
Predicate space dimensionality: 600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 0 seconds (tp:14,fp:0)
Predicate space dimensionality: 800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 0 seconds (tp:21,fp:0)
Predicate space dimensionality: 1000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 0 seconds (tp:29,fp:0)
Predicate space dimensionality: 1200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:37,fp:0)
Predicate space dimensionality: 1400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:51,fp:0)
Predicate space dimensionality: 1600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:63,fp:0)
Predicate space dimensionality: 1800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:67,fp:0)
Predicate space dimensionality: 2000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:75,fp:0)
Predicate space dimensionality: 2200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:79,fp:0)
Predicate space dimensionality: 2400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:86,fp:0)
Predicate space dimensionality: 2600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:90,fp:0)
Predicate space dimensionality: 2800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:94,fp:0)
Predicate space dimensionality: 3000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:98,fp:0)
Predicate space dimensionality: 3200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:97,fp:0)
Predicate space dimensionality: 3400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:100,fp:0)
Predicate space dimensionality: 3600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:100,fp:0)
Predicate space dimensionality: 3800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 1 seconds (tp:100,fp:0)
Predicate space dimensionality: 4000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 2 seconds (tp:100,fp:0)
FPR [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
TPR [0.05, 0.02, 0.14, 0.21, 0.29, 0.37, 0.51, 0.63, 0.67, 0.75, 0.79, 0.86, 0.9, 0.94, 0.98, 0.97, 1.0, 1.0, 1.0, 1.0]

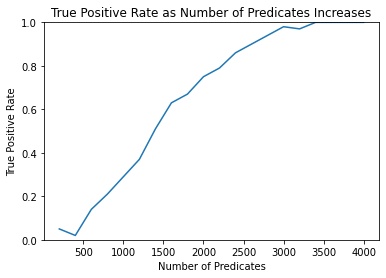
The attack is more than effectively demonstrated at 4000 predicates, which gives an ~0% FPR and >80% TPR. It is trivial to increase the number of predicates or size of the reference sample to further increase the power of the attack.
Differential Privacy#
We now adjust our query interface to return answers protected by differential privacy. execute_dp_query releases an estimate of the mean for each predicate. The implementation splits the budget evenly over all input columns. By linear composition, the total privacy expenditure of the joint release of all means works out to be epsilon. As the number of attributes increases, the number of queries increases, which commensurately increases the noise scale.
[15]:
import opendp.prelude as dp
from functools import lru_cache
dp.enable_features("floating-point", "contrib")
epsilon = 1.
@lru_cache(maxsize=None)
def find_meas(size, num_queries):
epsilon_per = epsilon / num_queries
input_domain = dp.vector_domain(dp.atom_domain(bounds=(0., 1.)), size=size)
mean = dp.t.make_mean(input_domain, dp.symmetric_distance())
scale = dp.binary_search_param(
lambda s: mean >> dp.m.then_base_laplace(s, k=-40),
d_in=2, d_out=epsilon_per)
return (input_domain, dp.l1_distance(T=float)) >> dp.m.then_base_laplace(scale, k=-40)
def execute_dp_query(data):
"""Computes the dp means of `data`.
Assumes the number of rows is public information
The total privacy expenditure is `epsilon`."""
exact_aggregates = data.mean(axis=0)
base_laplace = find_meas(*data.shape)
return np.array(base_laplace(exact_aggregates))
Run the simulation once more with this new query interface.
[18]:
num_predicates = np.arange(1, 11) * len(population) * 4
fp_results, tp_results = simulate_attacks(
execute_dp_query,
membership_attack_fig_1,
sample_size=5,
reference_size=50,
num_predicates=num_predicates,
num_trials=100,
delta=0.05)
print("FPR", fp_results)
print("TPR", tp_results)
plot_fpr_tpr(num_predicates, fp_results, tp_results)
Predicate space dimensionality: 400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 2 seconds (tp:58,fp:49)
Predicate space dimensionality: 800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 3 seconds (tp:52,fp:51)
Predicate space dimensionality: 1200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 4 seconds (tp:52,fp:48)
Predicate space dimensionality: 1600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 5 seconds (tp:48,fp:46)
Predicate space dimensionality: 2000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 6 seconds (tp:44,fp:50)
Predicate space dimensionality: 2400
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 8 seconds (tp:41,fp:53)
Predicate space dimensionality: 2800
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 10 seconds (tp:58,fp:55)
Predicate space dimensionality: 3200
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 12 seconds (tp:42,fp:57)
Predicate space dimensionality: 3600
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 19 seconds (tp:40,fp:43)
Predicate space dimensionality: 4000
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ~ 31 seconds (tp:51,fp:41)
FPR [0.49, 0.51, 0.48, 0.46, 0.5, 0.53, 0.55, 0.57, 0.43, 0.41]
TPR [0.58, 0.52, 0.52, 0.48, 0.44, 0.41, 0.58, 0.42, 0.4, 0.51]
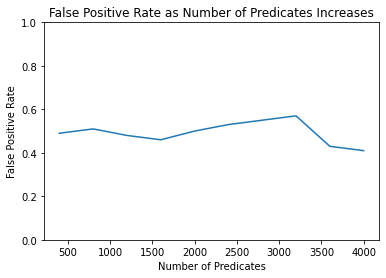
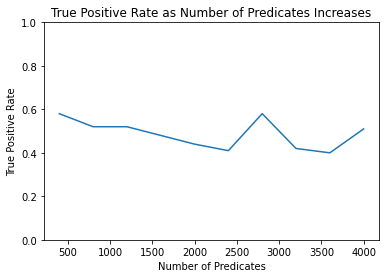
The resulting graphs show that the membership attack is thwarted. The response from the test is practically a coin-flip; it fails to identify Alice as a member of the sequestered dataset about half the time, and falsely identifies Anita as a member of the dataset about half the time.